


In the world of artificial intelligence, few innovations have captured the imagination quite like Large Language Models (LLMs). These sophisticated systems have revolutionized how we interact with technology, enabling machines to understand and generate human-like text with remarkable fluency. But what exactly powers these marvels of modern technology? In this article, we embark on a journey to unravel the mechanics behind LLMs, shedding light on the inner workings of these fascinating creations.
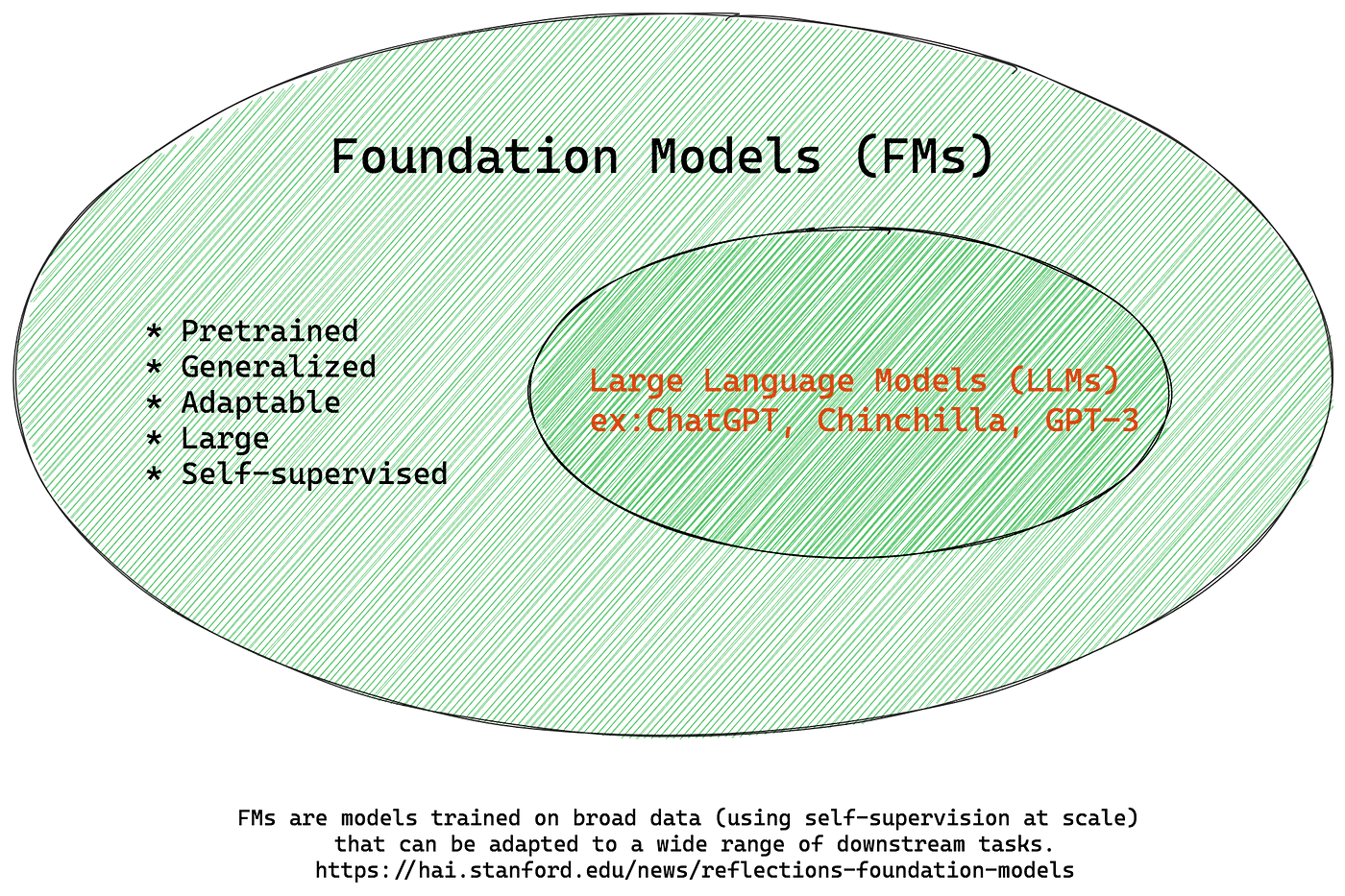
The Foundation of LLMs
Deep Learning At the heart of every LLM lies a foundation of deep learning—a subfield of artificial intelligence inspired by the structure and function of the human brain. Deep learning models, such as neural networks, are designed to mimic the complex interconnectedness of neurons in the brain, enabling machines to learn from vast amounts of data.
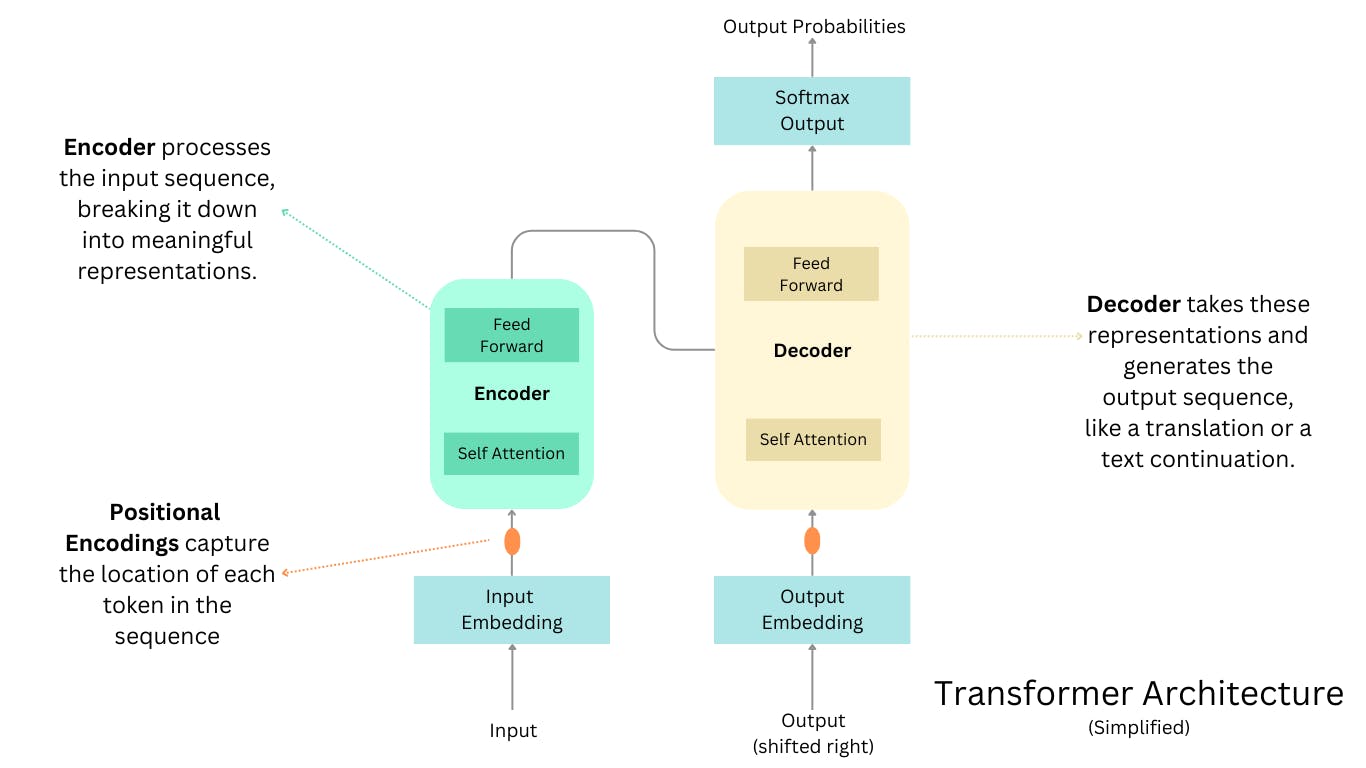
The Architecture
Transformer Models One of the most influential architectures powering LLMs is the Transformer model. Introduced in the seminal paper "Attention is All You Need" by Vaswani et al., Transformer models revolutionized natural language processing (NLP) by leveraging the concept of self-attention mechanisms. These mechanisms allow the model to focus on different parts of the input text, capturing long-range dependencies and contextual information more effectively than previous approaches.
Training Process
Massive Data and Computational Power Training an LLM involves feeding it with massive amounts of text data—ranging from books and articles to websites and social media posts. This data serves as the foundation upon which the model learns the intricacies of language. However, processing such vast quantities of data requires immense computational power, often necessitating specialized hardware like Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs).
Fine-Tuning and Transfer Learning
Tailoring LLMs for Specific Tasks While pre-trained LLMs possess a remarkable understanding of language, they can be further fine-tuned for specific tasks through a process known as transfer learning. By exposing the model to task-specific data and fine-tuning its parameters, developers can customize LLMs for applications such as language translation, sentiment analysis, or question-answering systems.
Challenges and Ethical Considerations Despite their incredible capabilities, LLMs are not without challenges and ethical considerations. Issues such as bias in training data, misuse of AI-generated content, and the potential for deepfakes raise important questions about responsible AI development and deployment. It is crucial for developers and policymakers to address these concerns proactively, ensuring that LLMs are used ethically and responsibly.
Looking Ahead
The Future of LLMs As research in artificial intelligence continues to advance, so too will the capabilities of LLMs. Future iterations may incorporate innovations such as multimodal learning (integrating text with other forms of data, such as images or audio) or enhanced understanding of context and commonsense reasoning. With each breakthrough, LLMs inch closer to achieving a deeper understanding of human language and cognition.
Large Language Models represent a pinnacle of artificial intelligence, pushing the boundaries of what machines can achieve in understanding and generating human-like text. By exploring the mechanics behind LLMs—from their deep learning foundation to their training processes and ethical considerations—we gain a deeper appreciation for the complexities involved in creating and deploying these remarkable systems. As we continue to unlock the potential of LLMs, it is essential to approach their development and use with care, ensuring that they serve as tools for positive impact and progress in our increasingly digital world.